
- Joined
- Apr 15, 2019
- Messages
- 375
- Likes
- 758
It could have trivially done that as well. But the market doesn't want that. The market wants the files as created in the "studio" as that sounds like it is better. What you are saying is why the hotel customer doesn't drink tap water instead of paying $5 for the Fuji bottle on the table. Even if they taste the same, some want the Fiji water thinking they are in a paradise for a minute or two.Don't change the value prop and then ask why they did this. They did it because there is market demand.
Also, they conducted controlled test showing that filtering of high-res audio 44.1 khz can have audible effects:
“The audibility of typical digital audio Filters in a high-fidelity playback system,” [peer reviewed] Convention Paper, Presented at the 137th AES Convention 2014
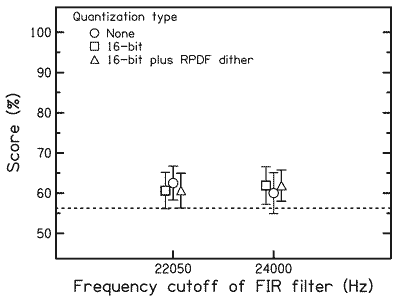
The dotted line was p < 0.05:
“The dotted line shows performance that is significantly different from chance at the p<0.05 level [5% probability of chance] calculated using the binomial distribution (56.25% correct comprising 160 trials combined across listeners for each condition).”
Not a home run as far as night and day but passes the standard used in research for audibility. This paper was published a year or two before MQA as a format was announced so it laid the foundation for why this format should exist.
This is a funky paper.
First of all, research has shown that young people (19-25 yo) can hear up to 28kHz (link).
Here are the conditions and one sided T test results from the paper. I think the way they did Table 2 has a funny smell. Still, let's take it at face value.


According to Table 2, the "hardest to distinguish" was 24kHz filter with no dither. Maybe that was expected. The "easiest to distinguish" was 24kHz filter with 16 bit quantization plus dither.
The paper says there were 8 test subjects aged from 25 to 65, with no breakdown. But looking at the scores (about 60-65% success rate), it's pretty plausible that if there were two 25 year olds with good hearing among the test subjects, one would expect the outcome of the paper. I wish they would have plotted the ability to hear the difference vs subject age.
Even though this paper seems to be saying that high frequency content is important in music, I think it's actually showing that young people can hear a 22-24kHz filter. That's all.
The other stuff (quantization and dither) is well within error bars and nothing can be said about it.
It makes good marketing for hi-res music though: "Oh look, people* can hear beyond CD frequencies."
But let's conveniently hide the fact that * = young people