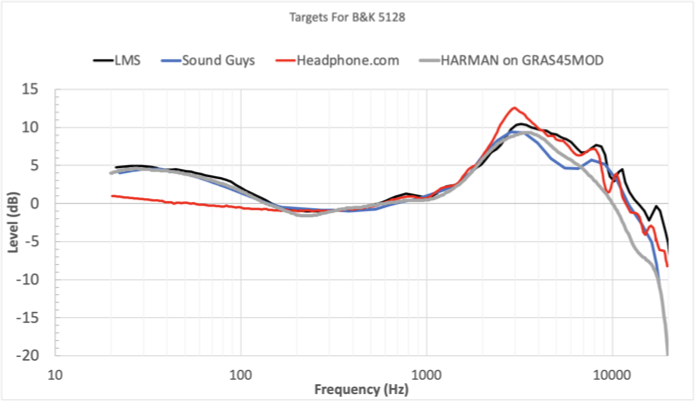
Also, here's a bonus game of spot the odd one out:
I'm surprised that you can even read this graph since it wasn't normalised at 500Hz. OMG Harman is massaging the data !
I'm also surprised since you like to nitpick that you didn't notice that Harman's digitisation work must have been a bit rushed as there are some differences between these targets that don't make a lot of sense given how they were designed. Not that it should matter for the point you're making, the errors are too negligible for that.
They've done some research on the 5128 already, and produced an extrapolated
target that you all at headphones.com have derided. Maybe before you poo-poo it, how about demonstrating that your target is any better with at the very least a lower mean predicted preference rating error than the 5.8 points that this 5128 target from Harman has in relation to the predicted ratings from the original GRAS measurements and Harman target as Sean has shown.
A properly designed target for the 5128 won't have a lower predicted preference rating error than what Harman obtained for a given set of headphones precisely because the method Harman used is
intrinsically designed to produce the lowest error possible, on average, for that set. It's a purely logical outcome of the methodology used. Now the issue is that using a different set of headphones, they'd have gotten a different target (particularly when comparing coupling insensitive headphones to coupling sensitive ones), and of course now you'd get a larger error with the first set.
You can visualise this problem fairly easily by dividing the set of 20 headphones Harman used to produce their 5128 target in two subsets of 10 headphones and apply the same methodology for both :
Here very deliberately choosing to put the majority of coupling insensitive headphones in one and coupling sensitive headphones in the other.
Since the sample of 20 headphones Harman used to design this 5128 target comprises a majority of coupling sensitive headphones, you end up with the rather weird situation where their 5128 target, in spite of its low predicted score error vs the predicted score on 711, is not coherent with Harman's own listening tests,
for reasons already developed in this thread (using HP.com's 8dB / tilt in that post, things would be a bit different now that they're rather aiming for a 10dB/tilt).
You considered above that HP.com's target is an outlier vs. the other targets put forth, well, Harman's own 5128 target would be just as much.
So yep it should be poo-pooed, it's a particularly nonsensical methodology.
Now the thing is, since HP.com's target also is quite a departure from the results of Harman's listening tests, you could leverage the same criticism against it, at least until additional listening tests have been performed, which is why as far as I'm concerned, I'd be a bit more comfortable with LMG's target for now as a preliminary target, until proven otherwise. You're just late to the party.
Of course even that's a fairly low bar, and what you'd actually need to empirically substantiate the casually thrown around claim that the 5128 provides a more accurate representation of human headphone perception/preference than GRAS is a correlation between predicted and actual preference ratings of greater than the high 86% Harman achieved using their GRAS rig and target for it
I sense a confusion here between assessing whether or not the 5128 is a more accurate representation of how headphones behave on real humans, which should be evaluated with in-situ measurements, and whether or not the combination of a fixture, a target and a predictive model are more effective than others at predicting people's preferences.
I find it quite funny that you always seem to qualify the r number Harman's predictive model resulted in as "high" as if you had to convince yourself that it's a great achievement, I'm still puzzled why some people express it as a percentage, which doesn't make a lot of sense to me, and I am not expecting you to intelligently engage with anything I'd write about it, but if the following was a predictive model designed to rank people by height from tallest on the left hand side to lowest on the right hand side, I think most of us would consider it rather perfectible to say the least.
That's what the OE model achieved, and that's before any consideration of coupling issues come into play.
When you combine the degree and the distribution of errors the model makes with this (ie inter-individual variation at the blocked ear canal entrance) :
You end up with something of very little value in my opinion, even if its not unreasonable to think that this is the best publicly available predictive model we know of today.
Ie, if I show you this :
You basically have no way of knowing, using the predicted score, which one of these will actually be preferred by a majority of listeners, as you don't know the error the predictive model made for each (degree and direction, ie positive or negative), and don't know from the score alone their in-situ behaviour.
(as well as the high 85% virtualization correlation,
Harman's
validation for the OE virtual methodology relies on this data, with the scores obtained with the real headphones in blue, and the scores obtained with the virtual method in green (with the r number expressed as it should, not in percentages) :
The tests actually included a larger number of participants, but only some of them participated in both tests, if we include them all the results are the following :
I have not digitised the data for that already but I'm pretty certain that I'd get similar if not worse errors than the predictive model above once scaled similarly (which might not be that easy to do properly...).
This is a fascinating article, but rather for the questions it raises than the conclusions it seems too eager to reach in my opinion.
For example, why is it that in regards to HP4 (K550), the authors write this :
When whether using the data from all listeners or only the ones who participated in both tests, it's actually the HPs that scored the most similarly, even though we know from Harman's own research that the K550 is quite susceptible to coupling issues and measures in situ quite differently from how it measures on ear simulators (and therefore how it would have been reproduced by the virtual HP method). But is it really scoring the most similarly or are we seeing the effects of the listeners not using the scale in the same manner between both tests, among other variables ? If so, how can we scale it properly without the presence of anchors in both tests ? In comparison, why is it that no tentative explanation was given for HP5's scores, even though it's the one with the most discrepancy ?
and that was with the old KB007X too, before they moved to more anthropomorphic pinnae which would likely increase this correlation even higher).
That's possible, but also speculative, particularly given the set of headphones Harman used for the virtualisation validation test. For one of them (K550), it's actually one of the few headphones for which the Welti pinna was less representative of the on-head behaviour than the older pinna.
There's a reason why Harman is now very much focused, among other considerations, on the question of coupling issues, they've finally realised that it's a major issue, particularly for the type of headphones they intend to sell. They wouldn't bother to perform in situ measurements if measuring headphones on a fixture and running a predictive model was all you needed to predict preferences and if their virtual HP methodology was all you needed to subjectively evaluate a particular pair of headphones.