Careful about that "research." That was what Mad_ told me so I let him create a target based on one of these papers for 5128 only to realize the results were not making sense after I started testing headphones.
I'm not terribly keen to jump to the defense of a curve I threw together from on paper in a moment...but what the heck, let's look at some comparisons.
This is the
HD650 you measured in 2020 on the 5128 fed into the 2018 model but with my "synthetic" 5128 Harman target as the target response
Here by comparison is your measurement on the 45CA against the 2015 target (which was the basis for the target I provided you in 2020)
And here is
Keith Howard's measurement of the HD650, which found a spread in PPR encompassing both results (likely, based on the differing ear gain on his measurements, due to either very different placement or severe defect of one channel).
If it would be of interest to people, I can perform the same for the HE400i, ether CX, and so on - coupling variation will of course be a factor (and, again, should people like, we can replicate this sort of thing with our 43AG and 5128 - indeed, this is part of my intended internal testing of our targets).
It took significant effort across many years and countless research projects for Dr. Olive and crew to come up reasonable target curves. One-shot research may not apply I am afraid. Don't be tempted to make my mistake.
This really isn't true, though - the "RR1_G" target was produced in
2013, in one of the first few papers, and was strongly preferred! While the Harman work refined subsequent targets, its primary notable feature was
controlling for a ludicrous number of variables across subsequent studies (which was a very good thing to do, and we all owe Sean a debt of gratitude for his efforts).
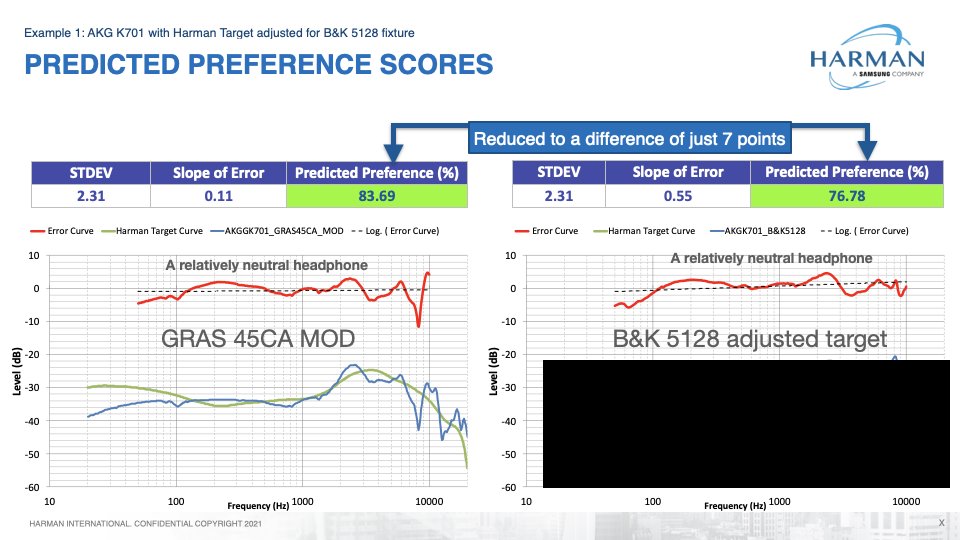
Also note that even with the adjusted target, one does not get the same preference score with the two fixtures (84 vs 77)
This adjusted target is simply based on an average difference for headphones in the dataset, so tautologically unless they all varied the same way, it was going to vary substantially - in that case, the headphone in the plot had
smaller variations than several of the outliers left in the dataset, otherwise it would have come closer. Ultimately, using headphones on different rigs cannot reveal a transfer function between them (because no such thing exists), but that also isn't what we really should be looking for to begin with...
All of that is not looking like something that is effectively doing a lot of predicting in my view ?
From my POV this is pretty harsh - all predictive models are flawed, and there are always outliers, but the PPR model is pretty good! It gets the "shape" of things generally right, with good headphones trading places somewhat, and a couple of headphones rated as being much worse than they were heard to be - odds are you could avoid those "false negatives" with some refinements to the algorithm (and, indeed, the slightly more complex in-ear model has fewer of them).
You're very unlikely to build a perceptual model that's perfect in predicting human responses to complex stimuli, IMO - but one which can look at FR and spit out a generally not-too-far-off ranking of headphones is quite an innovation! An imperfect but still significantly better than guessing (and, if you want my two bits, probably better than "dead reckoning" based on plots) model is a useful starting point for future development!

 ! That such a model has a decent correlation with the actual scores and trends sensibly is the least we should expect from it (duh !).
! That such a model has a decent correlation with the actual scores and trends sensibly is the least we should expect from it (duh !).