
-
Welcome to ASR. There are many reviews of audio hardware and expert members to help answer your questions. Click here to have your audio equipment measured for free!
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
A chat with Dr. Floyd Toole
- Thread starter hardisj
- Start date
- Joined
- May 21, 2019
- Messages
- 4,036
- Likes
- 6,880
This has been done to ensure accuracy during single tone testing.The other question you raised is interesting. It occurs to me that signal processing could be used to nullify distortion, if the distortion characteristics of the drivers are very will understood.
Klippel have developed something more complex along these lines as well. Haven't followed it closely, though.
amen
I do find it interesting/comforting that two of the leading researchers in psychoacoustics essentially say “meh” about distortion. Especially since Geddes spent so many years researching it and coming up with a very high correlating metric for it. (Geddes’ chat is below for this who missed it)
Over the years I have found that compression is more important and tends to be what I hear when I hear problems that aren’t otherwise linked to. Take, for example, the Klipsch Fives powered speaker with a built in limiter that I have reviewed. It has relatively medium distortion in the LMF. But it also has a lot of limiting. 2dB or more even in the lower midrange to Midbass. What did I hear? The limiting, by far. And this was well before I had a clue that such a limiter was built in.
IOW, compression is far more important to me than distortion. Namely because it directly shows up in frequency response as a linear non-linearity. We all know the impact of FR. And that jives with what Geddes told me when we had our chat.
that said, I will continue to provide HD results since it’s so easy to generate as well as IMD/Multitone for transducers in hopes that one day it can be useful in some way. But it isn’t anything I feel is a necessity as I do about compression/limiting.
Chat with Dr. Earl Geddes of GedLee Audio
I finished watching the interview with Dr. Toole and I greatly appreciate your doing that and making it available. It was the high point of my otherwise boring day.
DonH56 made a short comment that sort of hits the nail on the head. When it comes to distortion, context matters. Are we talking about the amount of distortion a speaker makes when SPL at one meter is 70 dB, or about the amount of distortion at 100 dB? Obviously it is different, and this is the reason why the idea that distortion isn't important doesn't seem a useful idea to me. We need to have some way to quantitatively describe how loud a given speaker can play, before it doesn't sound good anymore. And we know that the reason the speaker stops sounding good at a certain point is the distortion, which is different at a given SPL for different speakers. How else are you going to make this assessment, and describe it quantitatively, except by making distortion a crucial concept? If someone asks, "What do you mean exactly when you say that the speaker can't play louder than 100 dB?" How are you going to answer this kind of question, except by making it about distortion? If there is a way to do this without referring to distortion, I don't know what it is.
I'm also a little puzzled by the distinction between distortion and compression (or by drawing a distinction between a driver's distortion and its linear excursion range). Non-linear distortion implies the presence of spectral content not present in the test signal, which occurs when the signal is misshapen, i.e., when a perfect sinusoidal looks almost like a perfect sinusoid but it is little bit flattened at the top. The misshapen waveform contains spectral content in addition to the original pure tone(s). It seems to me that this isn't inherently different from what occurs with compression. I just don't understand the distinction. I suppose that someone could say that the non-linear behavior of the driver leads to compression of the signal and that the compression of the signal is the "reason" for the distortion. Another person would by-pass the mention of compression and say that the non-linear behavior of the driver is the reason for the distortion. This seems like an area where causality is a matter of how you decide to look at it. But that observation is besides the point I suppose. I'm just trying to say that it wouldn't occur to me to draw a distinction between compression and distortion. If you hear compression, are you not hearing distortion?
- Joined
- May 21, 2019
- Messages
- 4,036
- Likes
- 6,880
Beam control has been implemented in combination with wavefield synthesis to achieve just this kind of control at audio frequencies: https://www.audiosciencereview.com/forum/index.php?threads/holoplot-x1-matrix-array.23186/ I believe in one demonstration they also used parabolic mirrors to control perceived direction as well.What is potentially realistic and potentially done in some sound bars is the use of DSP to implement different phase shifts for the individual drivers, to compensate for the varying distances from the listener to the individual drivers. Said differently, by varying the phase for the individual drivers, it may be possible to make the forward-radiating beam spread out wider. I wrote "may be possible" because I'm not at all certain this is possible. If you think about phased-array radar, differential phase shifts applied individually to the individual radiating elements makes it possible to steer the beam. But the narrow directivity of the beam is due inherently to the overall dimension of the array compared to the wavelength, and also due to the nature of electromagnetic radiation. There are speakers nowadays that use multiple tweeters in an array, the implication being that it is possible to control the beam width by controlling the phase offsets among the individual drivers. I have decided whether I believe this is believable. Even the ability to steer the beam in a phased-array radar is possible because there is just one wavelength. For a given, specific wavelength, it is not difficult to see how relative phase of different radiating elements could be used to steer the beam, and if this can be done to steer the beam, maybe it is possible to steer the beam to the right from the elements on the right and to the left from the elements on the left. Maybe. And maybe it is possible to do this sort of thing even for wavelengths covering a range of an order of magnitude or greater.
In general, dense transducer arrays seem to be the forefront of new research in 3D audio. I find it really sad that they are limited to research institutions for now. No way to hear one in action until the pandemic lifts.
restorer-john
Grand Contributor
I'm also a little puzzled by the distinction between distortion and compression (or by drawing a distinction between a driver's distortion and its linear excursion range). Non-linear distortion implies the presence of spectral content not present in the test signal, which occurs when the signal is misshapen, i.e., when a perfect sinusoidal looks almost like a perfect sinusoid but it is little bit flattened at the top. The misshapen waveform contains spectral content in addition to the original pure tone(s). It seems to me that this isn't inherently different from what occurs with compression.
Distortion and compression are quite different in speakers.
Compression occurs due to voice coil temperature altering the overall efficiency (and spectral output) of the drivers. A driver that was efficient when cold, will be less efficient when hot. The base level distortion inherent in the driver may vary little during that time. Voice coils, magnet structures and crossover components are all susceptible.
In smaller speakers, the effects of compression are enormous in my experience, up to and including the levels (and duration) required to introduce significant audible THD.
If the so-called "preference" ratings among speakers are done at low (80s) levels, they aren't worth a red-cent.
Blaspheme
Senior Member
- Joined
- Apr 14, 2021
- Messages
- 461
- Likes
- 517
Captions help people who are hearing-impaired, and generally.Or, you can just watch the damn video without complaining about it.
Yes, I know this is an audio-focused forum, doesn't matter.
OP
- Thread Starter
- #47
Captions help people who are hearing-impaired, and generally.
Yes, I know this is an audio-focused forum, doesn't matter.
i get it. It was tongue in cheek.
But I don’t have the time to make a transcript. Someone else already did, though.
Blaspheme
Senior Member
- Joined
- Apr 14, 2021
- Messages
- 461
- Likes
- 517
For sure, I saw the smiley!i get it. It was tongue in cheek.
But I don’t have the time to make a transcript. Someone else already did, though.
The suggestion from MZKM was to turn on auto-caption, which I didn't think of, but was a good idea (assuming it works of course, I have no experience posting to YouTube). Also assuming all you have to do is enable a function, not type a transcript.
I downloaded the transcript NTK generated. Not too bad.
Last edited:
thewas
Master Contributor
- Joined
- Jan 15, 2020
- Messages
- 8,198
- Likes
- 22,953
Both technologies you mention have been implemented to commercial soundbars, for example the driver distortion reduction by precompensating the signal appropriately (of course with obvious limitations) at some recent Samsung modelsThe other question you raised is interesting. It occurs to me that signal processing could be used to nullify distortion, if the distortion characteristics of the drivers are very will understood. But only up to a limit, and the limit is probably fairly tight. The problem is that the idea suggests that it would be possible to get unlimited volume from an arbitrarily small speaker by nullifying the distortion. Intuition is sufficient to realize that this is not possible, and from this it follows that the ability to do this kind of thing successfully would be limited to a very small increase in the volume level that can be achieved before the distortion becomes intolerable. The question is only what that small increase in volume would be exactly. 3 dB? 6 dB? When you consider how much greater the excursion of a speaker diaphragm has to be, for a doubling of power (+3 db), I think that the improvement that is inherently possible is probably not greater than 3 dB.
What is potentially realistic and potentially done in some sound bars is the use of DSP to implement different phase shifts for the individual drivers, to compensate for the varying distances from the listener to the individual drivers. Said differently, by varying the phase for the individual drivers, it may be possible to make the forward-radiating beam spread out wider. I wrote "may be possible" because I'm not at all certain this is possible. If you think about phased-array radar, differential phase shifts applied individually to the individual radiating elements makes it possible to steer the beam. But the narrow directivity of the beam is due inherently to the overall dimension of the array compared to the wavelength, and also due to the nature of electromagnetic radiation. There are speakers nowadays that use multiple tweeters in an array, the implication being that it is possible to control the beam width by controlling the phase offsets among the individual drivers. I have decided whether I believe this is believable. Even the ability to steer the beam in a phased-array radar is possible because there is just one wavelength. For a given, specific wavelength, it is not difficult to see how relative phase of different radiating elements could be used to steer the beam, and if this can be done to steer the beam, maybe it is possible to steer the beam to the right from the elements on the right and to the left from the elements on the left. Maybe. And maybe it is possible to do this sort of thing even for wavelengths covering a range of an order of magnitude or greater.
as well as beam steering since now almost 20 years at top Yamaha models called sound projectors (I even have one for my TV) which use wall reflections to emulate various surround channels:

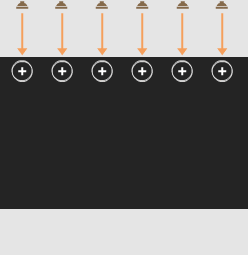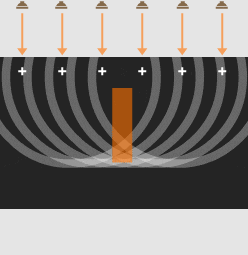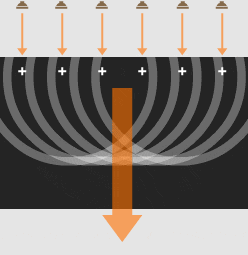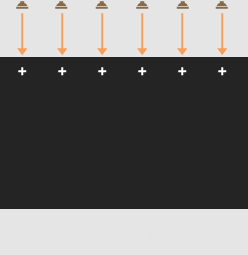
Sound waves overlap to produce one strong wave: a beam of sound.
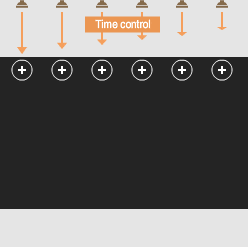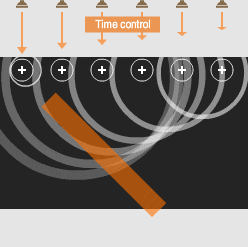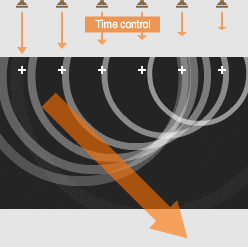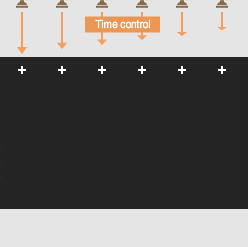
Adjusting the timing of the sound from each speaker gives control over the beam’s direction.
https://usa.yamaha.com/products/contents/audio_visual/ysp10th/chapter01/index.html
https://usa.yamaha.com/products/contents/audio_visual/ysp10th/chapter02/index.html
https://usa.yamaha.com/products/contents/audio_visual/ysp10th/chapter04/index.html
I find it amusing and sad at the same time that lower budget mass market audio equipment is usually more innovative and high tech than classic hifi/highend stereo.
Last edited:
For you maybe, not for me.I wish a transcript of many of these videos was available. It's so much faster to read than to watch.
")
Correct.For sure, I saw the smiley!
The suggestion from MZKM was to turn on auto-caption, which I didn't think of, but was a good idea (assuming it works of course, I have no experience posting to YouTube). Also assuming all you have to do is enable a function, not type a transcript.
I downloaded the transcript NTK generated. Not too bad.
It used to be pretty bad, but nowadays it’s really good, it‘ll even say something like [Music Playing] when it detects it and won’t try to transcribe the singer.
OP
- Thread Starter
- #52
For sure, I saw the smiley!
The suggestion from MZKM was to turn on auto-caption, which I didn't think of, but was a good idea (assuming it works of course, I have no experience posting to YouTube). Also assuming all you have to do is enable a function, not type a transcript.
I downloaded the transcript NTK generated. Not too bad.
Nope. No auto-captions available, at least not yet. Sometimes YT generates them and sometimes it doesn't. I don't know the rhyme or reason. I don't have the time to manually type them up. And since the one @NTK generated are questionable according to him, I'd rather not use them.
If someone here wants to volunteer their time they are certainly welcome to do so and I will use them.
/
restorer-john
Grand Contributor
I think it is in the process of generating it. YouTube states long videos won’t have them, but your ~2hr video with Christian and your ~1hr video with Earl has them. However, your video with Lars doesn’t (it’s like 3min longer than the one with Christian).Nope. No auto-captions available, at least not yet. Sometimes YT generates them and sometimes it doesn't.
Anywho, great video (though I wish more topics were covered; though it was time prohibited of course).
Last edited:
OP
- Thread Starter
- #55
I think it is in the process of generating it.
Hence the "... at least not yet".
So many posts about captions. You just gotta wait it out. Patience is a virtue.
Blaspheme
Senior Member
- Joined
- Apr 14, 2021
- Messages
- 461
- Likes
- 517
Indeed. The posts were informative though. I now know more about a process I was only dimly aware of previously. As is often the case, ASR forum tangents deliver.Hence the "... at least not yet".
So many posts about captions. You just gotta wait it out. Patience is a virtue.
audiofooled
Addicted to Fun and Learning
- Joined
- Apr 1, 2021
- Messages
- 644
- Likes
- 694
IIRC during one of his talks @j_j (pretty sure it was him, apologies if not) shared a story about setting up a PA for a party in his youth, and the crowd was asking to turn up the volume despite the system being at its limits. So he inserted a germanium diode into the circuit to increase the effective distortion. Although the output power didn't change, the spectrum did, due to nonlinearity, and the crowd was satisfied.
From my perspective, from reading and thinking about what I've heard myself, nonlinear distortion seems to have its primary effect on perceived loudness, with secondary effects on pitch and roughness when gross.
Geddes' comments on group delay were interesting but the only good research I know of is by Blauert from the late 70s, which gives audibility thresholds at 2 cycles or so, with some variation across the audible range. How this becomes an increase in perceived loudness I don't know.
Is this the primary cause for listener's fatigue as well? Subjectively, I find sound of most PA systems I heard over the years very fatiguing, and I always thought it was because of too much SPL, but could it be because of the perceived loudness due to nonlinear distortion? Do professional systems tend to have more of this or are they simply just cranked too loud?
At home I get this effect that it's never too loud and have to use common sense or body sensation to know when it's loud enough. Another sign would be when stuff in the kitchen start to rattle. I rarely ever listen at this level but even then it's so much different and never fatiguing... I just have to turn it down because kitchen utensils start to get annoying.
Geert
Major Contributor
- Joined
- Mar 20, 2020
- Messages
- 2,238
- Likes
- 4,494
PA's are a whole different game where a lot might be going on:Is this the primary cause for listener's fatigue as well? Subjectively, I find sound of most PA systems I heard over the years very fatiguing, and I always thought it was because of too much SPL.
- Speakers where sound quality is compromised for max SPL
- Speakers or speaker arrays with serious directivity issues and comb filtering
- Often limited low end extention (no real sub)
- Difficult to provide uniform coverage
- No ideal stereo listening position for most of the audience
- Terrible room acoustics
- Systems continously driven at (or beyond) the max of their capabilities
- Stage crosstalk spilling in the mic's as well as the FOH sound
- Insufficient budget and time to do a good job (PA is a low budget business)
The thing with PA's is you need to work with what you have, so you need to make a lot of compromises. That might lead to a sound made to cut through everything.
Things have improved a lot with modern line array systems and in-ear monitoring.
audiofooled
Addicted to Fun and Learning
- Joined
- Apr 1, 2021
- Messages
- 644
- Likes
- 694
That might lead to a sound made to cut through everything.
True.
I watched/listened to the chat yesterday. It was a great and interesting discussion. Good job.
One thing I will mention for those that may be like me is that this can be listened to instead of watched. I tend to listen to podcasts when I am working on mindless tasks. The video with Christian I listened to, but I think it needs to be watched as well. Probably need to go over that one a couple of times to really understand the NFS.
In that vein, Erin might want to note whether a video can be listen only.
One thing I will mention for those that may be like me is that this can be listened to instead of watched. I tend to listen to podcasts when I am working on mindless tasks. The video with Christian I listened to, but I think it needs to be watched as well. Probably need to go over that one a couple of times to really understand the NFS.
In that vein, Erin might want to note whether a video can be listen only.
Similar threads
- Replies
- 30
- Views
- 3K
- Replies
- 126
- Views
- 13K
- Replies
- 62
- Views
- 7K
- Replies
- 16
- Views
- 4K