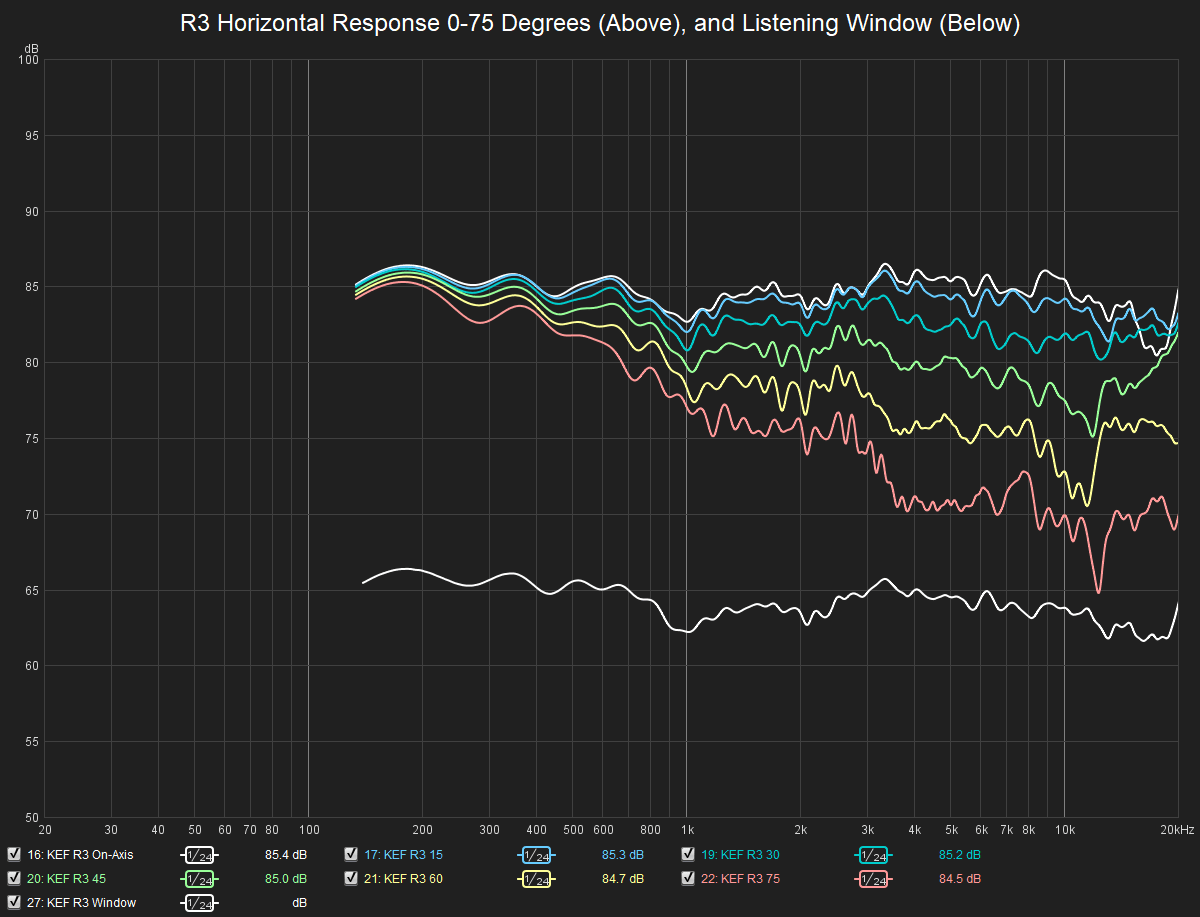
I would love to see such a large scale blind test experiment performed! Perhaps not necessarily with the KEF R3 vs Revel M16, but any such similar pair of two speakers where it seems the predicted preference (from measurements) doesn't seem to align with reality. For example, what if we find that the spins show that a KEF R11 should be preferred over a Revel Salon2? If such a prediction is made from the preference score, I think it would be valuable to actually take such an example and test it thoroughly in a blind test.I believe some of what appears to be a disconnect between the excellent measurements of the R3 and our host's preference for the M16 which has very good measurements but noticeably below the R3 is we are looking at the preference on one person. The research has shown if a group of people blind tested these two speakers more would prefer the R3 to the M16. Of course, it would not be every single listener in the test.
I'm a little less certain than some here that the preference scores we're seeing will perfectly predict the outcome of such a large-scale blind test for every pair of speakers, perhaps because I work in an industry where we fit statistical models / train machine learning models all the time -- and I understand and have seen first-hand the plethora of ways in which such models can fail to make reliable predictions outside of the set of data the model was fit to.
I could write extensively about statistical models vs objective science, but in short: It seems that many fellow objectivists here forget that while the raw measurement data is objective, preference scores are not objective truth, they are statistical models. No matter how good those models are, there is likely some room to improve them.
But again, regardless of how we interpret them regarding predicted speaker preference, the measurements themselves are objective and intrinsically valuable -- and I'm super excited to watch as this site builds an increasingly large collection of high quality data here!
Last edited: