- Thread Starter
- #121
I can program Fourier transforms, when the situation warrants. I have the education and training. I am a software developer with some audio physics classes. I can be as technical as the situation calls for.
I am just looking for some confirmation to prove the concept that a neutral speaker can be colored from my RME DAC PEQ without too much pain. All the PEQ does is transform some input. I want to apply a musical scale transform. Transform seems like a more appropriate term than color. I think a "smoothing function" is more descriptive than transformation function. Just smooth the input according to the Do-Re-Mi scale. You could consider a smoothing function as automated mastering process editing. All of the scales can be mathematically calculated, which would be a true DSP function. The goal is a more analog, than linear curve. Emotionless is a synonym for a flat or linear frequency response curve. The human voice is analog. Analog is difficult to edit manually.
This is quite funny, because I thought I was doing something wrong, when the Ut queant laxis music pushed me towards a similar curve.
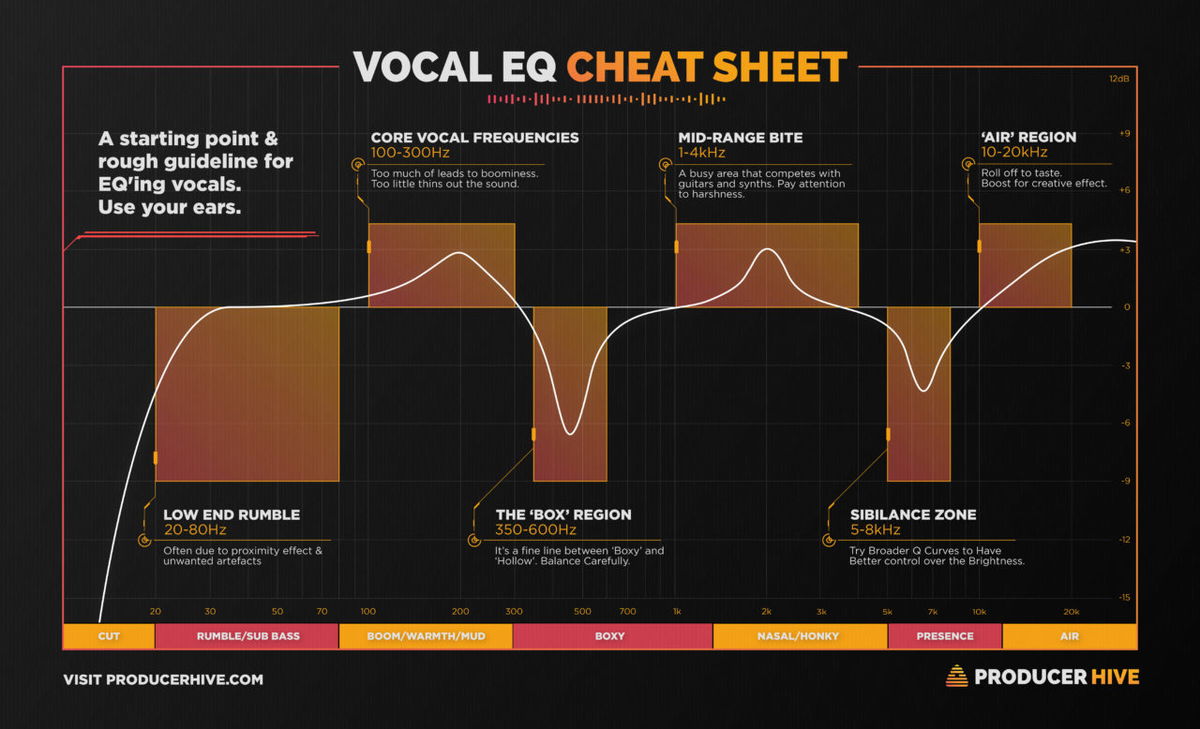
I am looking for a speaker that is good at generating "Vocal EQ". My guess is a speaker that lends itself for speech therapy.
When sophisticated software and hardware is necessary, then it can be brought to bear. Conceptually, a musical scale transform seems very straight forward, but I don't really know more than I can reason about.
I am actually more interested in how the brain encodes sound, than how machines do. I think the answer is straight forward. Regular expressions are the natural function of neural networks. Regular expressions are the essence of perceived sound. Music is the pleasant version. For example, when I rode my bike past the train crossing this morning, the bell makes a "ding, ding, ding" sound. That pattern is a regular expression. Bird express regular sound patterns as "chirp, chirp, chirp".
I like to operate from the standpoint of models. Here is a model that might have general applicability, including rooms.
https://en.wikipedia.org/wiki/Source–filter_model
The source–filter model represents speech as a combination of a sound source, such as the vocal cords, and a linear acoustic filter, the vocal tract. While only an approximation, the model is widely used in a number of applications such as speech synthesis and speech analysis because of its relative simplicity. It is also related to linear prediction. The development of the model is due, in large part, to the early work of Gunnar Fant, although others, notably Ken Stevens, have also contributed substantially to the models underlying acoustic analysis of speech and speech synthesis.[1] Fant built off the work of Tsutomu Chiba and Masato Kajiyama, who first showed the relationship between a vowel's acoustic properties and the shape of the vocal tract.[1]
An important assumption that is often made in the use of the source–filter model is the independence of source and filter.[1] In such cases, the model should more accurately be referred to as the "independent source–filter model".[citation needed]