
Keith_W
Major Contributor
Dear mods: I looked for another thread describing Krol's method but I was surprised that I could not find one. If there is an existing thread, would you be kind enough to merge it?
Krol et al published a paper in 2013 describing this method. This paper is available for download from ASR here.
Krol notes that Maximum Length Sequence measurements (commonly known as logarithmic sweeps) have a lower frequency limit imposed by reflecting boundaries. He proposed an alternative method via delay-sum beamforming. Essentially, the microphone is shifted in a straight line towards the loudspeaker and the measurement is repeated multiple times. The idea is that the direct sound from the speaker remains correlated, but the reflections are not. If the responses are summed, the influence of reflections is reduced.
As the microphone gets closer to the speaker, the time of flight delay will be reduced. The measurements will need to be adjusted for delays. The delay can be calculated with t = d/c where t is time in seconds (multiply by 1000 for milliseconds), d is the distance between microphone and speaker in meters or feet, and c is the speed of sound (343m/s, or 1125 ft/s). Rotate each measurement by the calculated delay.

Krol's paper includes a comparison between his described method and the anechoic response, shown above.
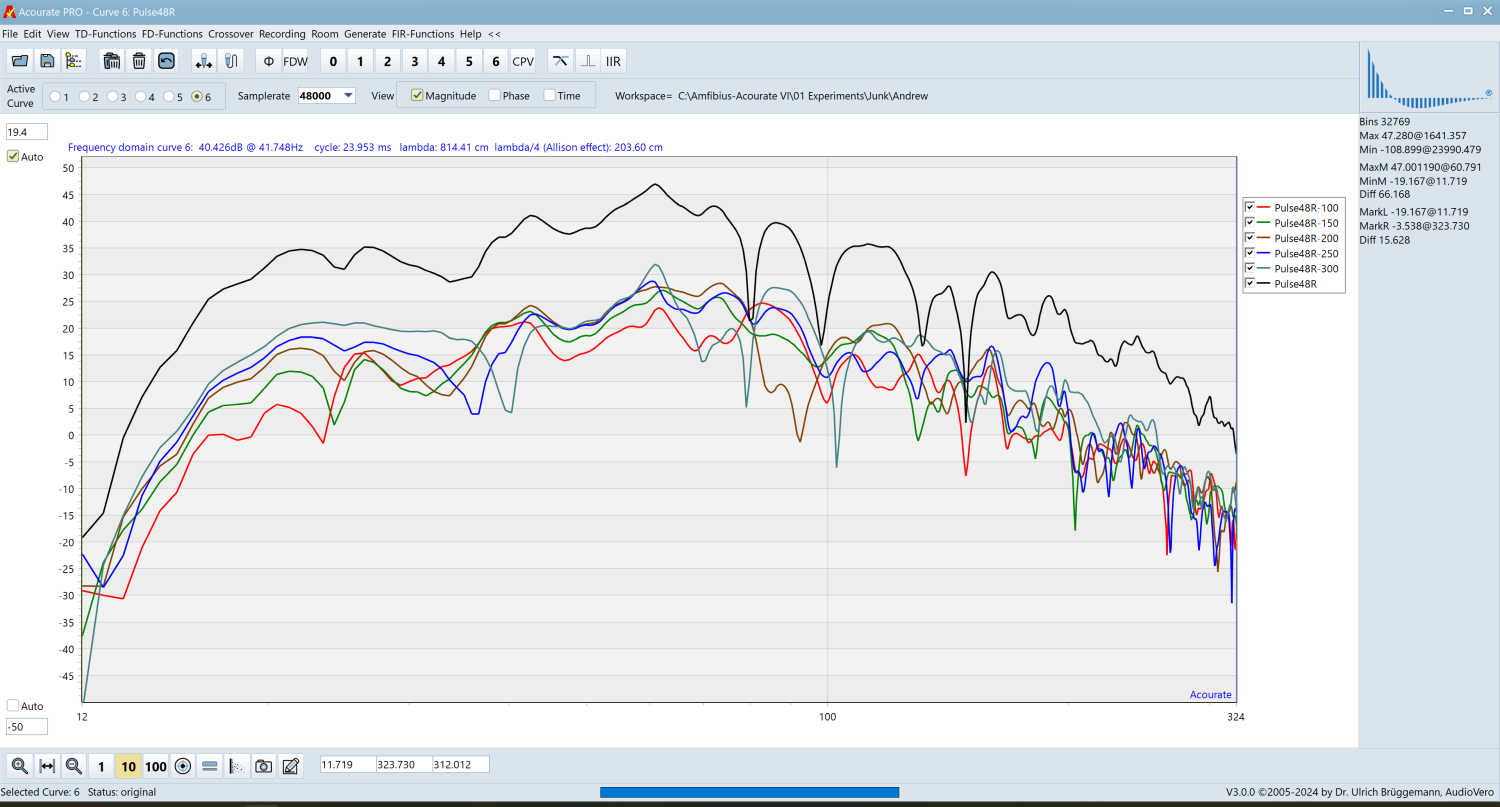
I tried this method at home. A tape measure was placed on the floor on the axis of the speaker. I wanted to avoid capturing the nearfield response, so I stopped measuring 1m from the speaker. Sweeps were taken at 25cm intervals. I then adjusted the delay of all measurements and summed them. I should theoretically adjust the gain, but I did not do so. The above illustration shows the sum (black curve) of multiple measurements (all the curves below) taken 25cm apart. Only the woofer was swept.
I thought that it would be even faster to perform an MMM instead of multiple logarithmic sweeps. The disadvantage of the MMM is that it captures the amplitude response only with no phase or timing information. This was not described by Krol in his paper. To my knowledge, there is no published documentation of this method comparing it to an anechoic response. So be warned - the method I am about to describe is unpublished and not peer reviewed. I am submitting this method to ASR for "peer review" so please be as savage as you like.
I started my software's MMM recorder and swept along a straight line on axis to the speaker.
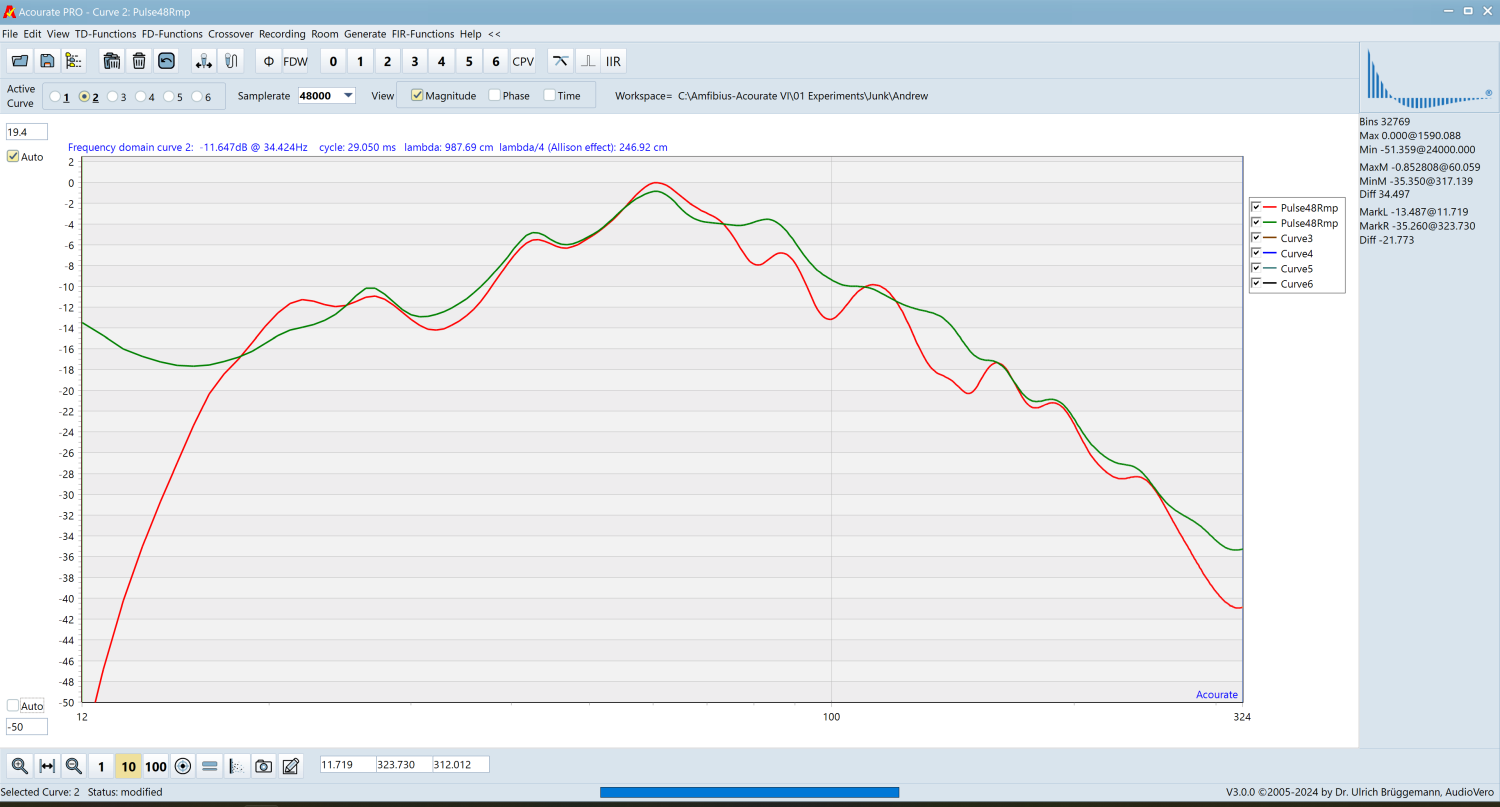
The above shows a comparison between Krol’s delay-sum method (red) and my proposed method using an MMM (green). There is acceptable correlation between the two methods. The rising bass response <20Hz is probably due to an artefact from microphone movement. I do not have an anechoic measurement for comparison.
My logic: if Krol's method compares favourably with the anechoic response, and the MMM method compares favourably with Krol's, then it should be a good approximation of the anechoic response.
Comments and criticism appreciated.
Krol et al published a paper in 2013 describing this method. This paper is available for download from ASR here.
Krol notes that Maximum Length Sequence measurements (commonly known as logarithmic sweeps) have a lower frequency limit imposed by reflecting boundaries. He proposed an alternative method via delay-sum beamforming. Essentially, the microphone is shifted in a straight line towards the loudspeaker and the measurement is repeated multiple times. The idea is that the direct sound from the speaker remains correlated, but the reflections are not. If the responses are summed, the influence of reflections is reduced.
As the microphone gets closer to the speaker, the time of flight delay will be reduced. The measurements will need to be adjusted for delays. The delay can be calculated with t = d/c where t is time in seconds (multiply by 1000 for milliseconds), d is the distance between microphone and speaker in meters or feet, and c is the speed of sound (343m/s, or 1125 ft/s). Rotate each measurement by the calculated delay.
Krol's paper includes a comparison between his described method and the anechoic response, shown above.
I tried this method at home. A tape measure was placed on the floor on the axis of the speaker. I wanted to avoid capturing the nearfield response, so I stopped measuring 1m from the speaker. Sweeps were taken at 25cm intervals. I then adjusted the delay of all measurements and summed them. I should theoretically adjust the gain, but I did not do so. The above illustration shows the sum (black curve) of multiple measurements (all the curves below) taken 25cm apart. Only the woofer was swept.
I thought that it would be even faster to perform an MMM instead of multiple logarithmic sweeps. The disadvantage of the MMM is that it captures the amplitude response only with no phase or timing information. This was not described by Krol in his paper. To my knowledge, there is no published documentation of this method comparing it to an anechoic response. So be warned - the method I am about to describe is unpublished and not peer reviewed. I am submitting this method to ASR for "peer review" so please be as savage as you like.
I started my software's MMM recorder and swept along a straight line on axis to the speaker.
The above shows a comparison between Krol’s delay-sum method (red) and my proposed method using an MMM (green). There is acceptable correlation between the two methods. The rising bass response <20Hz is probably due to an artefact from microphone movement. I do not have an anechoic measurement for comparison.
My logic: if Krol's method compares favourably with the anechoic response, and the MMM method compares favourably with Krol's, then it should be a good approximation of the anechoic response.
Comments and criticism appreciated.