
This is a topic that I expect some of the members in the forum who are in the medical field to also know. If so, feel free to contribute ") .
.
The outer ear is designed to collect and magnify the mid-range frequencies. This is the reason the equal loudness graphs of Fletcher Munson show much higher sensitivity in that region which naturally enables one to hear other humans better:
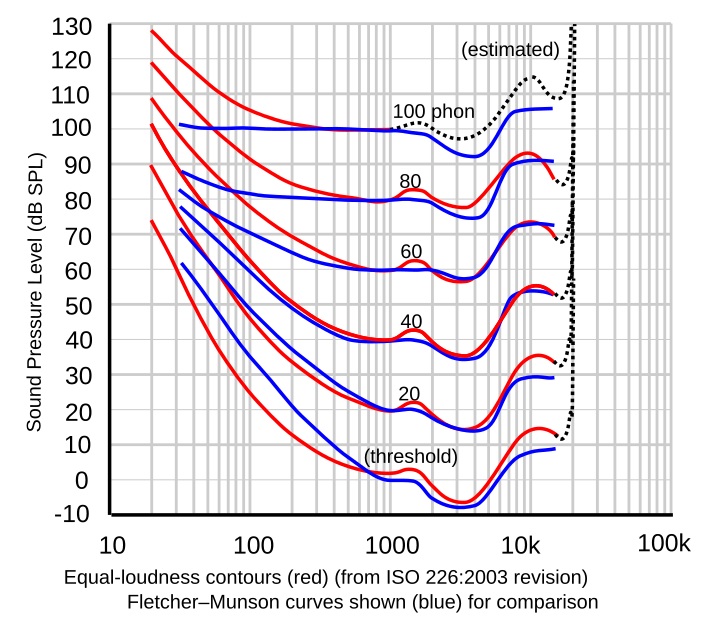
The effect is like cupping your hand around your ear to hear better. The "horn" effect created will best tune to frequencies of 1 to 5 Khz.
At this point we have air pressure inside the ear. That gets us to the middle ear which starts with the ear drum. This is an impedance matching system where it translates the high pressure but small movement of air molecules to high movement of the fluids in the inner ear that ultimately lead to us detecting sound.
There are two sets of hair cells. The outer hair cells (OHC) are not hairs in the classical sense in that they are connected at both ends. They play a critical role. Normally the maximum dynamic range that we can detect without that is about 60 db. This is computed based on thermal and other noises that set the lowest level sound we can hear, and the maximum movement that is possible. Yet, listening tests show that we can hear a dynamic range of 120 db. How do we go from 60 to 120? The outer hair cells enable that by creating a dynamic compression (as in volume compression). It is part of a clever positive mechanical feedback loop. The hairs actually lengthen or shorten/stiffen and loosen their structure to enable this dynamic range control:

The ultimate goal is to change the sensitivity of the inner hair cells that drive the nerves that feed the brain. Pretty cool system if you ask me!. BTW, I am trying to simplify the concepts here and provide generalized consensus around this area as I know it. Research is on going to model the ear and it remains challenging to fully do that.
At this point we are done with the ear and the next chapter is the brain. This thing is even more clever. The first thing happens is that all the data generated by the nerve system is captured "bit for bit" if you will in a short term storage memory. Little to no analysis of what is being heard is done at this stage. It is a simple dump of all data.
This short term store is called "echoic memory" because it allows the brain to revisit what has been captured. Ever ask someone to repeat something only to remember what they said? That is your brain going back to the echoic memory, re-analyzing what was captured and saying, "aha! now I get it." The echoic memory is able to store 4 to 5 seconds. Despite the short during in our terms, that is incredible amount of data that has been captured if you think about what it is recording.
The cognitive part of the brain then kicks in. It analyzes and chooses what it wants to store for medium and long term. Think of driving to work and someone cuts you off. You will remember that car, its color, etc. very well. But you will likely not remember any of the other cars you passed. We saw those other cars but the brain assigned little to no value in keeping that information. Same thing happens with sound. We choose to hear parts of the music. We likely miss significant details in the music which we may then pick up in subsequent listenings.
The cognitive process plays an important role in acoustics. The Haas effect that says we don't hear faded versions of a sound that come a few milliseconds later, e.g. a wall reflection, is the result of this analysis by the brain. If the two signals are similar in nature, the brain says, "this looks like a lousy copy of the louder sound so I am going to ignore it." Increase the time gap a ton and the brain decided the other event is different such as true echo in a large space. This is why room reflections are not what they seem to us on paper and in measurement systems. They lack the filtering that goes on in the brain.
How long does the echoic memory stays before decaying is under debate. I have seen estimates of a few seconds to 10 or even 20 seconds. This and the duration of the echoic memory have very important impact in AB switching audio tests. If I play A and then play B 1 minute later, the brain simply does not have proper recall of the other clip. If there are huge differences between them, then the brain may have stored that in long term memory. But if the differences are very small, there simply no recall of such detail as the echoic memory has long been wiped clean.
It is for the above reason that you hear the requirement for very fast switching between audio clips in AB testing. Speaking personally, I cannot pick small differences at all if the time is 1 seconds or more. I usually isolate a single item such as a single guitar pick, put it in a loop and then keep switching back and forth between two versions of it. That way, the echoic memory has a complete record of both sounds and it enables me to analyze them at whatever detail necessary. By looping I am constantly refilling my memory with both versions of the stimulus.
Now imagine a test where you hear one set of audio cables for a few minutes, stop, then put in another set of audio cables. By then there is no way we have perfect recall of the first system. That detailed memory is long gone. Much filtered version of it of course exists in the form of what song it was, what was played, etc. But nothing down to how that one 100 millisecond transient sounded. In that sense, any double blind AB tests that involves such long switching times is unreliable and favors the person not finding a difference as they get frustrated that they can't recall the other clip accurately enough. Again, if the differences are very large, then we can rely on mid and long term memory to detect it but in this case I am assuming that is not the case with cables in this example.
The above is readily apparent to anyone who has taken these blind tests. Do your own with an only ABX test of a compressed and uncompressed file and keep increasing the switching gap. No doubt the job gets harder and harder.
So what about the theory of "long term listening" being a better comparison? I don't know. It is possible that we commit to long term memory nuances that we recall when we perform such tests. It is also possible that we simply hear different things in each pass. When we hear system A, the brain picks different set of info from echoic memory than in the case of System B. That delightful note that we hear in the second system may have always been there in System A but we just did not unconsciously focus on it.
Anyway, this is what I know of the topic. I have on purpose skipped over a large chapter on how we actually detect sound and focusing on its capture and recognition. Appreciate comments, debates, info, etc.
.The outer ear is designed to collect and magnify the mid-range frequencies. This is the reason the equal loudness graphs of Fletcher Munson show much higher sensitivity in that region which naturally enables one to hear other humans better:
The effect is like cupping your hand around your ear to hear better. The "horn" effect created will best tune to frequencies of 1 to 5 Khz.
At this point we have air pressure inside the ear. That gets us to the middle ear which starts with the ear drum. This is an impedance matching system where it translates the high pressure but small movement of air molecules to high movement of the fluids in the inner ear that ultimately lead to us detecting sound.
There are two sets of hair cells. The outer hair cells (OHC) are not hairs in the classical sense in that they are connected at both ends. They play a critical role. Normally the maximum dynamic range that we can detect without that is about 60 db. This is computed based on thermal and other noises that set the lowest level sound we can hear, and the maximum movement that is possible. Yet, listening tests show that we can hear a dynamic range of 120 db. How do we go from 60 to 120? The outer hair cells enable that by creating a dynamic compression (as in volume compression). It is part of a clever positive mechanical feedback loop. The hairs actually lengthen or shorten/stiffen and loosen their structure to enable this dynamic range control:
The ultimate goal is to change the sensitivity of the inner hair cells that drive the nerves that feed the brain. Pretty cool system if you ask me!
. BTW, I am trying to simplify the concepts here and provide generalized consensus around this area as I know it. Research is on going to model the ear and it remains challenging to fully do that.At this point we are done with the ear and the next chapter is the brain. This thing is even more clever. The first thing happens is that all the data generated by the nerve system is captured "bit for bit" if you will in a short term storage memory. Little to no analysis of what is being heard is done at this stage. It is a simple dump of all data.
This short term store is called "echoic memory" because it allows the brain to revisit what has been captured. Ever ask someone to repeat something only to remember what they said? That is your brain going back to the echoic memory, re-analyzing what was captured and saying, "aha! now I get it." The echoic memory is able to store 4 to 5 seconds. Despite the short during in our terms, that is incredible amount of data that has been captured if you think about what it is recording.
The cognitive part of the brain then kicks in. It analyzes and chooses what it wants to store for medium and long term. Think of driving to work and someone cuts you off. You will remember that car, its color, etc. very well. But you will likely not remember any of the other cars you passed. We saw those other cars but the brain assigned little to no value in keeping that information. Same thing happens with sound. We choose to hear parts of the music. We likely miss significant details in the music which we may then pick up in subsequent listenings.
The cognitive process plays an important role in acoustics. The Haas effect that says we don't hear faded versions of a sound that come a few milliseconds later, e.g. a wall reflection, is the result of this analysis by the brain. If the two signals are similar in nature, the brain says, "this looks like a lousy copy of the louder sound so I am going to ignore it." Increase the time gap a ton and the brain decided the other event is different such as true echo in a large space. This is why room reflections are not what they seem to us on paper and in measurement systems. They lack the filtering that goes on in the brain.
How long does the echoic memory stays before decaying is under debate. I have seen estimates of a few seconds to 10 or even 20 seconds. This and the duration of the echoic memory have very important impact in AB switching audio tests. If I play A and then play B 1 minute later, the brain simply does not have proper recall of the other clip. If there are huge differences between them, then the brain may have stored that in long term memory. But if the differences are very small, there simply no recall of such detail as the echoic memory has long been wiped clean.
It is for the above reason that you hear the requirement for very fast switching between audio clips in AB testing. Speaking personally, I cannot pick small differences at all if the time is 1 seconds or more. I usually isolate a single item such as a single guitar pick, put it in a loop and then keep switching back and forth between two versions of it. That way, the echoic memory has a complete record of both sounds and it enables me to analyze them at whatever detail necessary. By looping I am constantly refilling my memory with both versions of the stimulus.
Now imagine a test where you hear one set of audio cables for a few minutes, stop, then put in another set of audio cables. By then there is no way we have perfect recall of the first system. That detailed memory is long gone. Much filtered version of it of course exists in the form of what song it was, what was played, etc. But nothing down to how that one 100 millisecond transient sounded. In that sense, any double blind AB tests that involves such long switching times is unreliable and favors the person not finding a difference as they get frustrated that they can't recall the other clip accurately enough. Again, if the differences are very large, then we can rely on mid and long term memory to detect it but in this case I am assuming that is not the case with cables in this example.
The above is readily apparent to anyone who has taken these blind tests. Do your own with an only ABX test of a compressed and uncompressed file and keep increasing the switching gap. No doubt the job gets harder and harder.
So what about the theory of "long term listening" being a better comparison? I don't know
. It is possible that we commit to long term memory nuances that we recall when we perform such tests. It is also possible that we simply hear different things in each pass. When we hear system A, the brain picks different set of info from echoic memory than in the case of System B. That delightful note that we hear in the second system may have always been there in System A but we just did not unconsciously focus on it.Anyway, this is what I know of the topic
. I have on purpose skipped over a large chapter on how we actually detect sound and focusing on its capture and recognition. Appreciate comments, debates, info, etc.