- Joined
- Jan 23, 2020
- Messages
- 4,335
- Likes
- 6,702
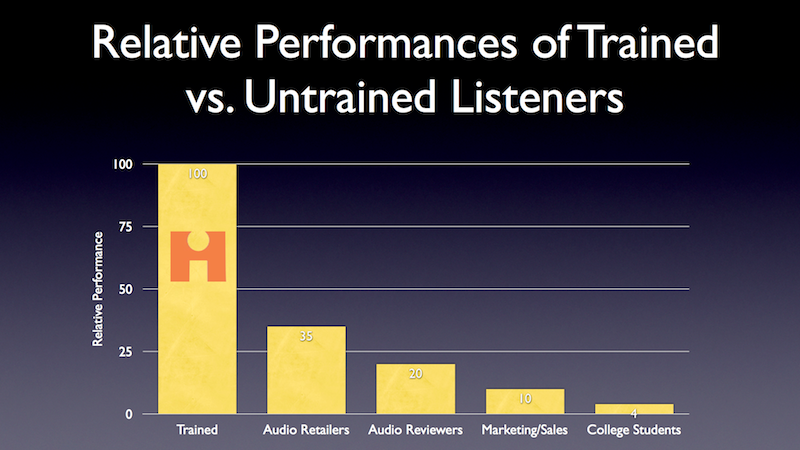
Spinorama is still super important and reliable indicator of performance. It is the "Olive Score" that is causing the confusion and what is at odds sometimes with my listening impressions.
We have a single number that takes multiple variables. By definition then you can get the same number with many variations of the underlying parameters. Those speakers can't sound the same.
Don't get me wrong, I agree 100% that it's super important. It's definitely still the most important measurement we have to evaluate speakers. I'm just saying that this site has shown that there's way more to speaker sound than what the spinorama can show, and that's somewhat contrary to what was said by Voeks/Toole/Olive in the "How to choose a loudspeaker. What the science shows" thread on AVS. We've now seen several examples of good spinoramas that sound bad, and several examples of bad spinoramas that sound good. To me, that says that the spinorama is insufficient for characterizing a speaker.
I agree that the Olive Score is by far the weakest aspect of the Toole/Olive science. The outdoor Revel speaker was horrible without EQ(way too bright) but it's excellent directivity made it easy to EQ, but the Olive score doesn't care about that.