HooStat
Addicted to Fun and Learning
Did you measure the speakers in the room? Just curious as to what that might look like. Very enjoyable to read about. Thanks for sharing.

Are you able to post the raw scores? Like to do a bit of statistical analysis on it.
I think it's a good idea for research center of some manufacturer (i.e. choosing dsp preset) , not for evaluation of commercially available speakers with mono downmix at reasonable level.To EQ the speakers as good as possible (FR not just level) and re-test, to see how much audible difference remains.
Did you measure the speakers in the room? Just curious as to what that might look like. Very enjoyable to read about. Thanks for sharing.
I mean EQing for FR in the given room, and then finding out how much difference remains. This is something manufacturers could do in their facilities, comparing with competitions' products, and maybe even do, but probably not many would want to publish the results (just a speculation).I think it's a good idea for research center of some manufacturer (i.e. choosing dsp preset) , not for evaluation of commercially available speakers with mono downmix at reasonable level.
Difference will be too small for good results.
I mean EQing for FR in the given room, and then finding out how much difference remains.
Average rating across all songs and participants:
Revel W553L: 6.6
KEF Q100: 6.2
JBL Control X: 5.4
OSD 650: 5.2
Plotted:
View attachment 147692
You can see that the Kef and Revel were preferred and that the JBL and OSD scored worse.
No I don't see that. The medians are so close and theres so much overlap on your box and whiskers plot that my initial interpretation was that your listeners were unable to reliably differentiate between the 4 speakers under blind conditions. You'd have to show statistics to say that any speaker was preferred.

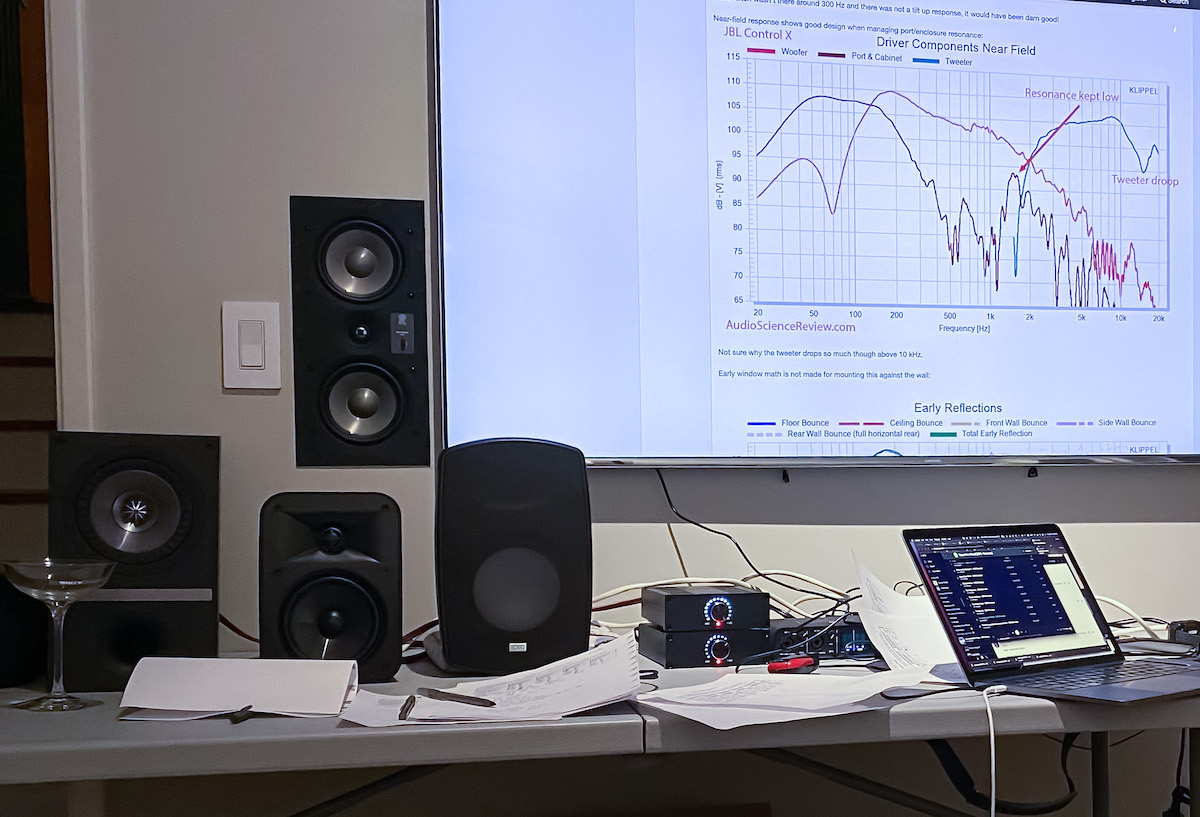
Nice work and effort, so first of all sincerely thank you for that, on the other hand what I have to criticise is the placement of the loudspeakers on the inner side of the table, please place them at least on its front edge next time (even better would be on seperate stands) as the large close and reflective horizontal surface will muddle up their FR and imaging.Here is a photo of what the setup looked like after we unblinded and presented results back to the participants:
I ran a quick F statistics test between a couple of samples. First was JBL Control X against KEF Q100. That difference is quite statistically valid with p value of 0.001.I think @amirm is going to run some additional analysis. Please weigh in with your own analysis as well.
Then we would have to decide how exactly and what will be EQ'd and this just adds up a lot of variables. Automatic DRC will measure and apply different filters with unpredictable results.mean EQing for FR in the given room, and then finding out how much difference remains
Not much really as i can see.I guess many of us are using room EQ/DSP, or at least have the possibility to do it.
For sure. They don't have hard reference (live sound), soft reference (good studio sound) or any understanding what is "good mastering". Speakers are artistic tools for them.Unfortunately it demonstrates that untrained/inexperienced listeners were unable to reliably differentiatet their loudspeaker preferences
In a discussion that I can't find anymore Amir was quoting some excerpts from an Olive study recommending C weighting for level matching, but I don't know what's the theory behind that.I'm curious as to whether A weighting wouldn't be a better choice. After all, if Speaker A had a bit more bass than Speaker B, using C weighting will mean the sensitive range 1-5k will probably be quieter for Speaker A during the listening tests. Wouldn't that (in general, if not every single time) lead to a preference for Speaker B, by dint of being set to play louder in the ear's sensitive band?
Applying my theory to the in-room responses you show, I would predict a preference order of KEF first, then Revel (close), then JBL, then OSD (with its suppressed 1-3 kHz).
That holds pretty close to your listening test result. Which means the preference order might have been due to the use of C weighting instead of A weighting for the level matching.
Interesting?